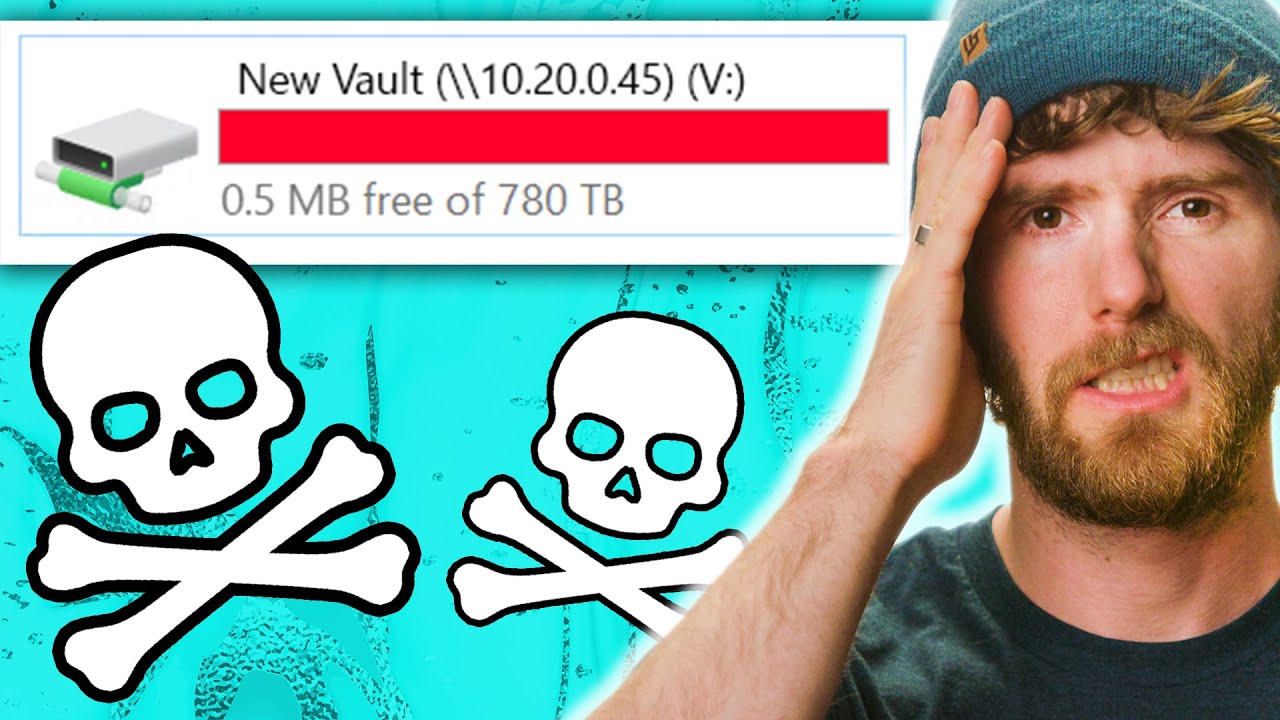
Our data is GONE... Again - Petabyte Project Recovery Part 1
0 up · 0 down · 0 ratings
Description
Configure your own workstation at lambdalabs.com
Promos
Check out Hetzner Cloud and use code LTT22 for $20 off at linustechtips.hetzner.com It's been a long time since we've had any serious data loss, but on this episode, we're discussing a software misconfiguration that has resulted in us losing an unknown amount of data on our petabyte project storage clusters. Discuss on the forum: linustechtips.com
Check out 45Drives at the links below Website: lmg.gg YouTube: lmg.gg Buy Seagate 20TB Exos Drives On Amazon: geni.us On Newegg: geni.us Purchases made through some store links may provide some compensation to Linus Media Group. ► GET MERCH: lttstore.com ► AFFILIATES, SPONSORS & REFERRALS: lmg.gg ► PODCAST GEAR: lmg.gg ► SUPPORT US ON FLOATPLANE: floatplane.com FOLLOW US ELSEWHERE --------------------------------------------------- Twitter: twitter.com Facebook: @LinusTech Instagram: @linustech TikTok: @linustech Twitch: twitch.tv MUSIC CREDIT --------------------------------------------------- Intro: Laszlo - Supernova Video Link: youtube.com iTunes Download Link: itunes.apple.com Artist Link: soundcloud.com Outro: Approaching Nirvana - Sugar High Video Link: youtube.com Listen on Spotify: spoti.fi Artist Link: youtube.com Intro animation by MBarek Abdelwassaa @mbarek_abdel Monitor And Keyboard by vadimmihalkevich / CC BY 4.0 geni.us Mechanical RGB Keyboard by BigBrotherECE / CC BY 4.0 geni.us Mouse Gamer free Model By Oscar Creativo / CC BY 4.0 geni.us CHAPTERS --------------------------------------------------- 0:00 Intro
Our data is GONE... Again - Petabyte Project Recovery Part 1] follows Linus Tech Tips as they confront a severe data loss incident in their petabyte-scale archival storage system. The video opens with a candid admission that despite their high-end hardware, misconfiguration and a lack of proactive maintenance led to irrecoverable data loss for parts of their Old Vault and New Vault storage clusters. They outline the scale of their operation, detailing two GlusterFS clusters spread across multiple Storinator servers housing thousands of drives, and explain that no complete backup existed for the affected data. The hosts emphasize the financial and logistical challenges of backing up a petabyte of data, and they announce an intent to rebuild a properly configured new 1.2 petabyte server using Seagate 20TB drives as a foundation for recovery. They also foreground the plan to consolidate data movement onto a fresh architecture, reformat the older vaults, and reattempt data migration once the new vault is online. Throughout, they acknowledge the responsibility and the learning opportunity, stressing the need for robust monitoring, regular scrubs, and formal IT ownership to prevent future incidents. The episode frames storage best practices as not just technical niceties but essential safeguards for a media operation that depends on reliable long-term data preservation, with a promise to document progress in upcoming parts of the recovery series. Finally, the hosts recur to their sponsorship and practical advice on reliable cloud and on-prem storage options, while setting expectations for a lengthy recovery process that could take weeks to months depending on data transfer needs and error rates. They close with a call to subscribe for updates and a teaser about revisiting the recovery steps in subsequent videos.
Topics · science & technology · data storage · disaster recovery · hardware infrastructure · video production
Questions answered
- What caused the data loss on the petabyte project servers?
- The data loss was caused by a misconfiguration and a lack of preventative maintenance that led to multiple drive faults and unrecoverable data in the ZFS pools.
- What is the planned approach to recover the data?
- They plan to build a new 1.2 petabyte server with updated drives and configurations, move data from the New Vault to the new system, reformat Old Vault, and then migrate data again, while implementing scheduled scrubs and backups going forward.
- Why wasn’t there a backup for the affected data?
- Backing up over a petabyte of data is extremely expensive, and at the time they did not have the backup solution in place or enough resources allocated for a duplicate array or cloud backup.